Autonomous AI-powered Anomaly Detection using Timeplus and DeepSeek-R1
- Gang Tao
- Mar 6
- 10 min read
Reasoning models like OpenAI's O1 and DeepSeek-R1 are specialized LLMs designed to enhance structured reasoning, problem-solving, and mathematical logic beyond standard chat-based models. They focus on improving multi-step reasoning and logical inference while maintaining efficiency.
Feature | O1 / DeepSeek-R1 (Reasoning Models) | Traditional LLM Chat Models (e.g., GPT-4, Claude, Gemini) |
Primary Focus | Structured reasoning, step-by-step problem-solving | General conversation and broad knowledge |
Architecture | Optimized for logical inference and multi-step calculations | Balanced between reasoning, creativity, and conversation |
Mathematical & Logical Strength | More accurate in solving math, coding, and scientific problems | Can make reasoning errors, struggles with complex logic |
Hallucination Reduction | Lower due to structured step-by-step reasoning | Higher risk of factual errors and hallucinations |
Efficiency | Often designed for faster and more structured responses | May take longer to generate structured reasoning chains |
Use Cases | Code generation, theorem proving, advanced problem-solving | General AI assistants, creative writing, broad Q&A |
DeepSeek-R1 has gained a lot of attention because it's one of the first open-source reasoning-focused LLMs that significantly improves inference efficiency and is free to use. R1 achieves high scores on benchmarks like MATH, GSM8K (grade-school math), and HumanEval (coding). Comparable or even better than some commercial models in logic-heavy tasks.
In today’s blog, I am going to show how to leverage Timeplus’s new Python UDF and DeepSeek-R1 running locally with Ollama, to detect IoT sensor anomalies, purely relying on DeepSeek’s prior knowledge. No rules, no threshold.
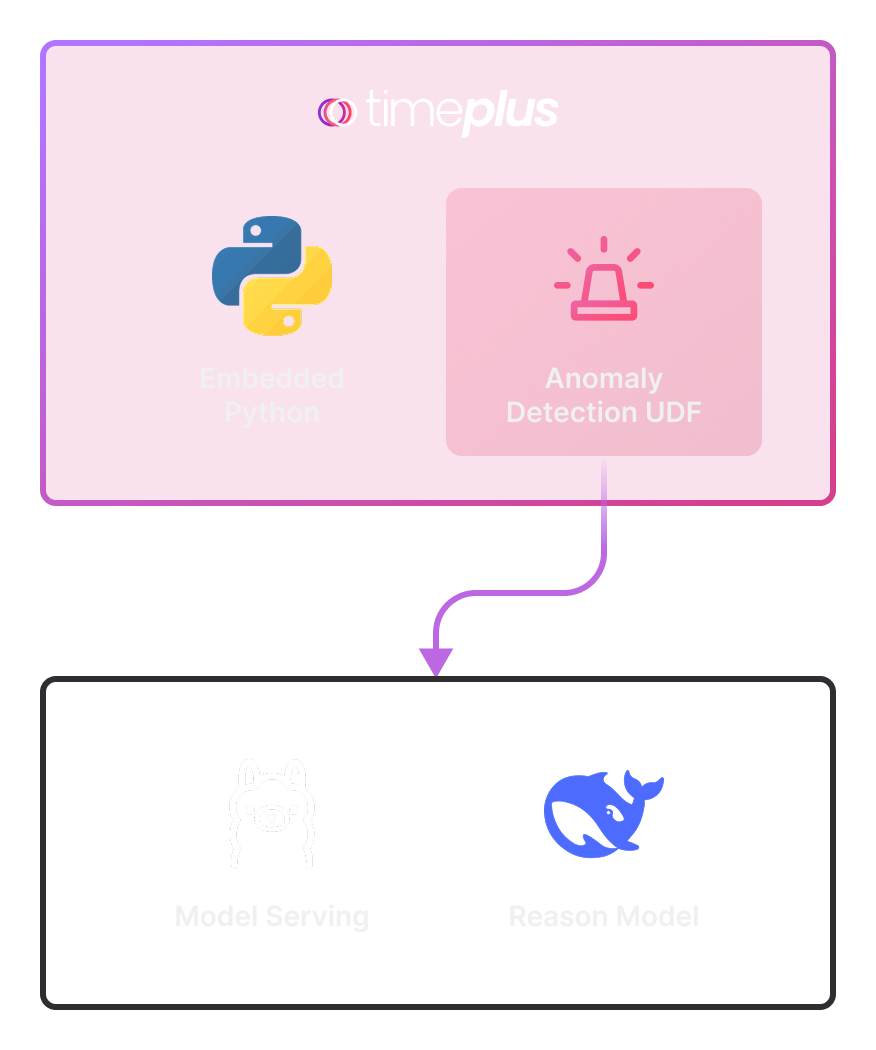
Overall Architecture
To run this anomaly detection, there are only two processes running locally:
Timeplus, which embeds a python interpreter and there are no external dependencies (other than installing the 3rd party dependencies like openAI), users can write python scripts as user defined functions and running in the SQL.
Ollama, as a model serving tool, provides access to different LLM running locally. In this sample, we will run deepseek-r1 with 7b parameters.
Data Preparation
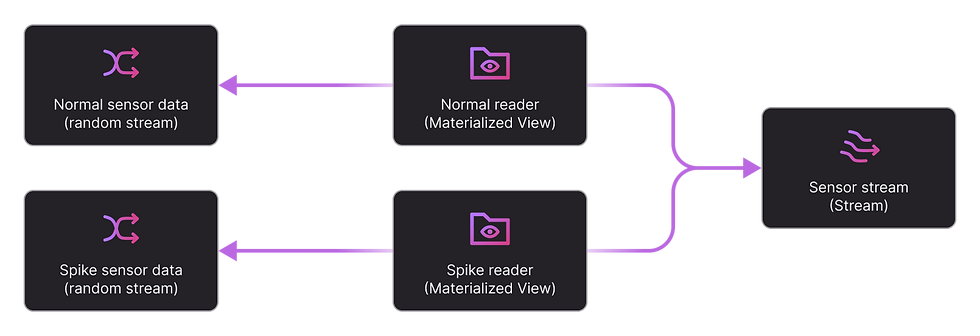
To simulate an IoT sensor that might have spike data
We created two random streams to simulate normal sensor data and spike sensor data separately.
`normal_sensor_data` stream will generate sensor value with mean 22 and variance 0.0 to simulate the normal value with very small shift
`spike_sensor_data` stream will generate sensor value with mean 50 and variance 1,1, to simulate the spike values that are significantly different from the normal value.
And then we create a stream sensor that used to receive the sensor data
Two Materialized Views are created to read data from two sensor data simulator
CREATE RANDOM STREAM normal_sensor_source
(
`ts` datetime DEFAULT now(),
`value` float64 DEFAULT round(rand_normal(22, 0.01),2)
)
SETTINGS eps = 1;
CREATE RANDOM STREAM spike_sensor_source
(
`ts` datetime DEFAULT now(),
`value` float64 DEFAULT round(rand_normal(50, 1),2)
)
SETTINGS eps = 0.1;
CREATE STREAM sensor
(
`ts` datetime ,
`value` float64
);
CREATE MATERIALIZED VIEW mv_read_from_senor_normal INTO sensor
AS
SELECT
ts, value
FROM
normal_sensor_source;
CREATE MATERIALIZED VIEW mv_read_from_senor_spike INTO sensor
AS
SELECT
ts, value
FROM
spike_sensor_source;By default, both random streams with normal data and spike data are collected into the sensor stream using the two MV. By pause/unpause the `mv_read_from_senor_spike`, we can simulate if there is spike data or not.
SYSTEM PAUSE MATERIALIZED VIEW mv_read_from_senor_spike
SYSTEM UNPAUSE MATERIALIZED VIEW mv_read_from_senor_spikeZero Shot Anomaly Detection using DeepSeek-R1
Traditional anomaly detection methods—such as statistical approaches, rule-based systems, and machine learning (ML) models—have been widely used in cybersecurity, fraud detection, IoT monitoring, and finance. However, these methods have notable limitations, and LLMs can enhance anomaly detection in several ways.
Rigid Rule-Based Systems
Static thresholds: Rule-based systems rely on predefined thresholds (e.g., CPU usage > 90% = anomaly).
Limited adaptability: Can’t detect new or evolving patterns.
High false positives: Normal variations can trigger unnecessary al
Statistical Approaches (e.g., Z-score, PCA, ARIMA)
Assumes normality: Many statistical models assume data follows a Gaussian (normal) distribution, which isn’t always true.
Poor at handling complex dependencies: Can’t detect anomalies in multivariate and non-linear relationships effectively.
Limited scalability: Computationally expensive for large, high-dimensional datasets.
Machine Learning-Based Approaches (e.g., Isolation Forest, Autoencoders, SVM)
Feature engineering is critical: Requires manual selection of features and domain expertise.
Data imbalance issue: Anomalies are rare, making it hard to get enough labeled examples.
Black-box problem: Many ML models (especially deep learning) lack explainability, making it hard to trust anomaly predictions.
By leveraging LLMs such as GPT or DeepSeek, there are some benefits compared with those traditional methods:
Context-Aware Anomaly ExplanationLLMs can explain anomalies in human-readable form.Example: Instead of just flagging a CPU spike, an LLM can analyze logs and say: "The CPU spike was caused by a sudden increase in API requests from a specific user."
Adaptive Learning Without Explicit RulesLLMs can dynamically learn new patterns without requiring hard-coded rules.Example: Instead of a static fraud-detection rule (e.g., “transactions above $10,000 are anomalies”), LLMs can adapt to user behavior and detect fraud even for lower amounts based on past patterns.
Zero-Shot and Few-Shot Learning
Traditional ML requires training on large labeled datasets.LLMs can detect anomalies with very few examples or even zero-shot by leveraging their pre-trained knowledge.
Here is the prompt we are going to use to detect the anomaly:
You are an AI assistant analyzing IoT sensor data for anomalies.
Given the following temperature readings from a factory sensor, identify if there are significant data anomalies and explain why.
Data:
Timestamp: 2025-02-13 18:10:10, Value: 22.51
Timestamp: 2025-02-13 18:10:11, Value: 21.77
Timestamp: 2025-02-13 18:10:12, Value: 22.67
Timestamp: 2025-02-13 18:10:13, Value: 48.96
Timestamp: 2025-02-13 18:10:13, Value: 21.35
Timestamp: 2025-02-13 18:10:14, Value: 21.81
Timestamp: 2025-02-13 18:10:15, Value: 22.49
Timestamp: 2025-02-13 18:10:16, Value: 22.7
Timestamp: 2025-02-13 18:10:17, Value: 23.04
Timestamp: 2025-02-13 18:10:18, Value: 20.73
Timestamp: 2025-02-13 18:10:19, Value: 21.91
Analyze:
1. Is there an anomaly?
2. If yes, explain why it is unusual.
3. List all the anomalous data points.
return the result in JSON, here is an example
```json
{
"is_anomaly" : True,
"reason" : "why it is anomaly",
"anomalous_data_points": ["Timestamp: 2025-01-01 18:10:13, Value: 108"],
}
```'''This is a typical case of zero shot learning where I did not specify which data is anomaly or not, we rely on LLM’s trained knowledge to judge whether there is anomaly or not.
If you run feed above prompt to your local DeepSeek-r1 model using Ollama, here is what you will get:
ollama run deepseek-r1
>>> You are an AI assistant analyzing IoT sensor data for anomalies.
... Given the following temperature readings from a factory sensor, identify if there are significant data anomalies and explain why.
...
... Data:
... Timestamp: 2025-02-13 18:10:10, Value: 22.51
... Timestamp: 2025-02-13 18:10:11, Value: 21.77
... Timestamp: 2025-02-13 18:10:12, Value: 22.67
... Timestamp: 2025-02-13 18:10:13, Value: 48.96
... Timestamp: 2025-02-13 18:10:13, Value: 21.35
... Timestamp: 2025-02-13 18:10:14, Value: 21.81
... Timestamp: 2025-02-13 18:10:15, Value: 22.49
... Timestamp: 2025-02-13 18:10:16, Value: 22.7
... Timestamp: 2025-02-13 18:10:17, Value: 23.04
... Timestamp: 2025-02-13 18:10:18, Value: 20.73
... Timestamp: 2025-02-13 18:10:19, Value: 21.91
...
...
... Analyze:
... 1. Is there an anomaly?
... 2. If yes, explain why it is unusual.
... 3. List all the anomalous data points.
...
... return the result in JSON, here is an example
...
... ```json
... {
... "is_anomaly" : True,
... "reason" : "why it is anomaly",
... "anomalous_data_points": ["Timestamp: 2025-01-01 18:10:13, Value: 108"],
... }
... ```'''
<think>
Okay, I need to analyze the given temperature readings for anomalies. Let me start by looking at the data provided.
The timestamps are consecutive seconds from February 13, 2025, around 6:10 PM. The values change slightly each second, but one value stands out: on 2025-02-13
18:10:13, there's a reading of 48.96. All the other readings are between 20.73 and 23.04, averaging around 22.
That peak value is much higher than the others. It could be an error in data collection or perhaps an unusual temperature event. Since it's significantly higher
without any context of a system failure, I'll consider it an anomaly.
</think>
```json
{
"is_anomaly": true,
"reason": "The temperature reading of 48.96 at timestamp 2025-02-13 18:10:13 is significantly higher than the surrounding readings, which are all below 24.",
"anomalous_data_points": [
{
"Timestamp": "2025-02-13 18:10:13",
"Value": "48.96"
}
]
}
```DeepSeek-R1 model found the anomaly point in this sample, there is no rule or threshold configured when we leverage this zero shot learning method.
In this case, we are running the DeepSeek-R1 model localling using Ollama, which is a lightweight, local LLM (Large Language Model) runner that makes it easy to run and interact with AI models on your own machine. It's optimized for performance and simplicity, allowing you to pull and run models like Llama 2, Mistral, Gemma, DeepSeek R1, and more with a single command. For more information, refer to https://ollama.com/library/deepseek-r1
Anomaly Detector Python UDF
Timeplus is a SQL-based stream processing and analytics engine, where SQL serves as the primary user interface, similar to a traditional database.
While SQL is a powerful language, it has certain limitations when handling complex business logic, such as:
Iterative or loop-based logic: Expressing loops in SQL can be challenging, especially without recursive CTEs.
Interacting with external systems: SQL does not provide a built-in way to call external functions written in other languages.
Accessing local files or network resources: SQL alone cannot directly interact with file systems or external network sources.
Leveraging existing ecosystems: Many data processing libraries, such as those in Python, offer advanced capabilities that are difficult to replicate in pure SQL.
This is why a User Defined Function (UDF) is a powerful tool that extends capabilities of SQL for some complex tasks.
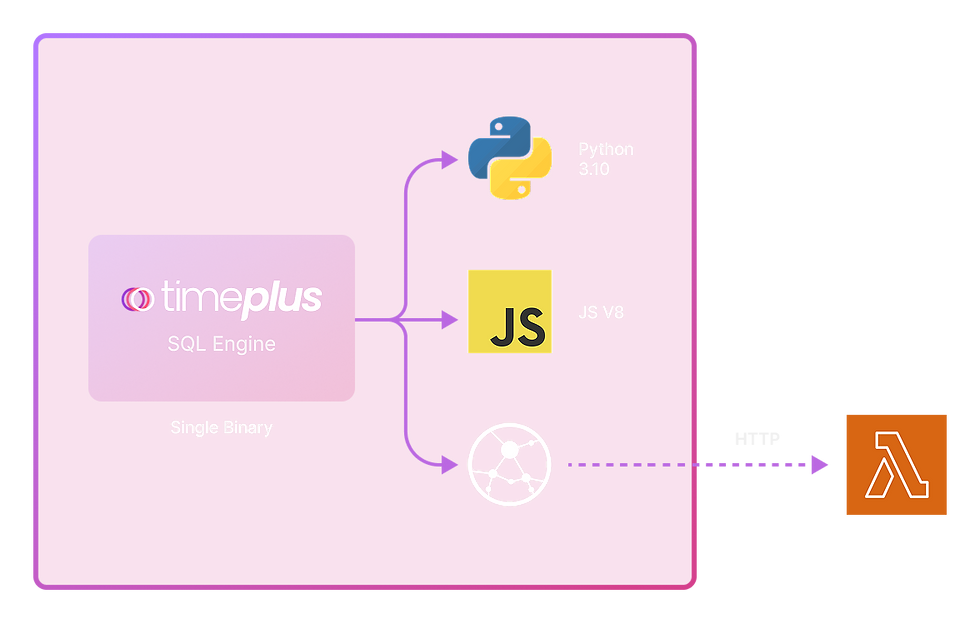
Timeplus already supports JavaScript UDFs by embedding the V8 engine, allowing users to write custom functions in JavaScript. However, in the Data and AI community, Python is the dominant language for data processing and machine learning. Introducing Python-based UDFs enhances Timeplus with greater flexibility and power, enabling more advanced real-time data processing. I am very excited that this new feature will be released in Timeplus 2.7.
Here is the used defined aggregation function to call DeepSeek for anomaly detection:
CREATE OR REPLACE aggregate FUNCTION anomaly_detector(ts datetime, value float64)
RETURNS string
LANGUAGE PYTHON AS
$$
import re
FROM string import Template
FROM openai import OpenAI
client = OpenAI(api_key="ollama", base_url="http://host.docker.internal:11434/v1")
def extract_code_blocks_with_type(markdown_text):
pattern = r"```(\w+)?\n(.*?)```"
matches = re.findall(pattern, markdown_text, re.DOTALL)
return [(code_type if code_type else "", code_content.strip()) for code_type, code_content in matches]
class anomaly_detector:
def __init__(self):
self.prompts = None
self.data_template = Template('Timestamp: $ts, Value: $value')
self.prompt_template = Template('''You are an AI assistant analyzing IoT sensor data for anomalies.
Given the following temperature readings from a factory sensor, identify if there are significant data anomalies and explain why.
Data:
$datapoints
Analyze:
1. Is there an anomaly?
2. If yes, explain why it is unusual.
3. List all the anomalous data points.
return the result in JSON, here is an example
```json
{
"is_anomaly" : True,
"reason" : "why it is anomaly",
"anomalous_data_points": ["Timestamp: 2025-01-01 18:10:13, Value: 108"],
}
```''')
self.datapoints = []
def serialize(self):
pass
def deserialize(self, data):
pass
def merge(self, other):
pass
def process(self, ts, value):
try:
for (ts, value) in zip(ts, value):
self.datapoints.append(self.data_template.substitute(ts=ts, value=value))
self.prompts = self.prompt_template.substitute(datapoints='\n'.join(self.datapoints))
except Exception as e:
self.prompts = (str(e))
def finalize(self):
messages = [{"role": "user", "content":self.prompts}]
try:
response = client.chat.completions.create(
model="deepseek-r1:latest",
messages=messages,
temperature=0.0
)
result = extract_code_blocks_with_type(response.choices[0].message.content)
return [str(result[0][1])]
except Exception as e:
return [str(e)]
$$;Let me explain how this code works:
`Create Function` defines a UDF by providing following information
Function name
Function input parameters name and type
Function output types
Function languages (JavaScript or Python)
Whether it is aggregation function or not
The code inside $$ and $$ is a string which is exactly what the python code will be called by the UDF.
The aggregate function is implemented using a Python class which has the same name as the function name
We set the base URL of openAI as `http://host.docker.internal:11434/v1`, this is because I am running the Timeplus locally in a docker container, and the Ollama is running locally on my Mac Book. the `host.docker.internal` can be used to access the local host within the container.
`__init__` function of the class initialize the state of the function, we keep the prompt template and the datapoints states in `self.datapoints`
We skip serialize, deserialize and merge method in this sample, for more information refer to https://docs.timeplus.com/py-udf#udaf
In the process method, we append the datapoints to the `self.datapoints` and update the prompt using the template, this process method will be called multiple times to do the aggregation jobs for all the data rows.
In the finalize method, we construct the prompt message and send it to the local LLM model, using the helper function `extract_code_blocks_with_type` to extract the JSON result from the LLM response and then return the final result.
After defining this UDF, user can call this aggregation function with a tumble window:
SELECT
window_start, anomaly_detector(ts,value) as anomaly, group_array((ts,value)) as datapoints
FROM
tumble(sensor, 30s)
GROUP BY
window_startNote, even DeepSeek has a very good inference performance, as it involves a long reasoning procedure, it takes like 20 seconds to do such inference in my local ollama running on Mac M2pro GPU. So it is a good practice to send aggregated results to LLM when you process your real-time data. In this case, we send the 30 seconds aggregation data to LLM to avoid too many calls to LLM.
When we turn run this spike MV, the DeepSeek Model can find those spikes, like this:
{
"is_anomaly": true,
"reason": "There are multiple instances where the temperature spikes significantly higher than usual, indicating possible irregular activity or sensor issues.",
"anomalous_data_points": [
{
"Timestamp": "2025-02-14 18:20:09",
"Value": "50.23"
},
{
"Timestamp": "2025-02-14 18:20:09",
"Value": "49.56"
},
{
"Timestamp": "2025-02-14 18:20:19",
"Value": "48.64"
}
]
}As in the 30 second window, we have inserted three spikes and the model found all of these anomalies. If we pause the spike MV and the detector provides the following result:
{
"is_anomaly": false,
"reason": "All temperature readings are within a consistent and expected range around 22.0 with no significant deviations.",
"anomalous_data_points": []
}The model can make some incorrect judgement as we did not clarify what "significant deviation" is. This means we may need to improve the prompt or provide more sample data (from zero shot to few shot) for normal and abnormal data.
{
"is_anomaly": true,
"reason": "There is one data point that significantly deviates from the expected temperature range.",
"anomalous_data_points": [
{
"Timestamp": "2025-02-14 18:27:24",
"Value": "21.98"
}
]
}We have now built an anomaly detector leveraging Python UDF and DeepSeek with less than 100 lines of code and we can integrate such checks seamlessly into my data processing pipeline using Timeplus SQL. This brings a new door to your real-time data processing.
Summary
In today’s blog, I have shown that the response from DeepSeek-R1 demonstrates its ability to detect anomalies purely based on its prior knowledge, without any pre-defined rules or thresholds.
There are some advantages of LLM-Based Anomaly Detection, this experiment highlights several key advantages of using LLMs like DeepSeek-R1 for anomaly detection:
Zero-Shot Learning: No need for labeled training data. The model can leverage its pre-trained knowledge to detect anomalies without manual thresholding.
Context Awareness: The model understands the concept of normal variation and extreme deviations, making it more robust than static rule-based systems.
Explainability: Unlike traditional machine learning models, LLMs can provide a human-readable explanation for why a data point is considered an anomaly.
Adaptability: Since LLMs can process various types of data, they can be extended to detect anomalies in different domains, such as network security, financial transactions, or industrial IoT.
While this method shows promising results, there are still areas for improvement, like improving the prompts, using few shot learning or even fine tuning your own model.
DeepSeek-R1, when used with Timeplus’s Python UDF and Ollama, provides an efficient and flexible approach to anomaly detection. Unlike traditional methods that rely on explicit rules and extensive training data, this approach leverages pre-trained knowledge for zero-shot anomaly detection. This experiment demonstrates how reasoning-focused LLMs can be a powerful tool for IoT monitoring and beyond, reducing dependency on static thresholds and improving adaptability to dynamic environments.
By continuously refining these models and integrating them with real-time data pipelines, organizations can build more intelligent, scalable, and automated anomaly detection systems.
Stay tuned for more insights on AI-driven anomaly detection and real-time data analytics!