Data Pipeline Architecture: Components & Diagrams Explained
- Timeplus Team

- Feb 2, 2024
- 10 min read
Companies are starting to see how important data is. But managing today's complex data systems needs a systematic approach to handle the entire data lifecycle, whether it is customer interactions, financial market trends, or operational metrics. The data pipeline architecture provides this structured framework that breaks down the silos of data sources and destinations.
However, constructing the optimal data pipeline is not an easy task in itself. The wrong approach will slow things down and decrease productivity. Even worse, if your pipeline is misaligned with the business needs, you will end up wasting time and resources. This shows how important it is to correctly set up the architecture from the start.In this article, we will look into data pipeline architecture and highlight its key components and how they function. We will also discuss the essential elements and technologies that make data pipeline architectures important for today’s businesses.
What Is Data Pipeline Architecture?

Data pipeline architecture outlines the complete framework and strategy for the flow of data within a system or organization, from its initial entry point to its final destination. It provides the blueprint that guides how raw data is acquired, processed, integrated, stored, and ultimately used for business objectives.
Data pipeline architecture serves as a roadmap for data engineers and developers. It guides them in creating effective and fully operational data pipelines that adhere to the specified architectural design.
This architecture is different from the actual data pipeline building. The architecture is a detailed plan while the pipeline is the real structure built following this plan where the outlined strategy is turned into a working system that handles data from start to finish.
An effective data pipeline architecture should outline details like:
The data sources that will feed into the pipeline, like databases, IoT sensors, and social media APIs.
Methods of data ingestion from those sources, like streaming versus bulk loads.
Appropriate data processing and transformation logic to prepare the data for usage.
Data storage choices aligned to use cases, like data lakes for ad hoc analysis or warehouses for business intelligence.
Tools and platforms required like ETL software, message queues, and workflow schedulers.
Monitoring and testing to uphold data quality standards.
Data security and privacy needs throughout the pipeline.
6 Major Components Of Data Pipeline Architecture
To carefully design each component of data pipeline architecture and its connections to the other components, we first have to understand them in detail. Let’s take a look.
A. Data Sources
Data sources are the starting points in a data pipeline where raw data is initially collected. The variety of sources can be extensive and each source plays a unique role in the data ecosystem. Sources can include:
Semi-structured data: Includes data like application server logs, messaging queues, and API streams. These help capture dynamic system events and user activities as they happen.
Structured data: Originates from relational databases and transactional applications and is crucial for basic business operations. It includes details like customer information, product catalogs, and order transactions.
Unstructured data: Covers a broad range, including documents, images, videos, audio, emails, and social media content. This data type is rich in information but lacks a predefined structure which makes it more complex to process and analyze.
B. Data Ingestion
Data ingestion acts as the entry point for data into the pipeline. It helps determine how you will process data. Depending on the data’s nature and urgency, the following methods can be used for ingesting data:
Batch loading: It can collect data at set intervals and is suitable for non-time-sensitive data.
Streaming: It captures data in real-time. It is essential for applications where immediate data analysis is critical, like fraud detection.
C. Data Processing
Data processing transforms raw data into meaningful insights. This stage is diverse and involves several important tasks, like:
Cleansing: Removing errors, duplicates, or irrelevant information to ensure the data quality and reliability.
Standardization: Involves converting data into a unified format for consistent data analysis.
Aggregation: Combining data from multiple sources for comprehensive analytics.
Applying business logic: Tailoring data to align with specific business objectives. This makes data actionable for decision-making.
D. Data Storage
Data storage is the foundation of any data system and is needed for data retention and retrieval. The choice of storage solution impacts data accessibility and analysis. Major types of data storage are:
Data warehouses: Optimized for query and analysis, they are essential for business intelligence applications.
Data lakes: Store large volumes of raw data in its native format and provide a high degree of flexibility for data scientists.
Non-relational databases: More flexible as they accommodate a wide range of data types. These are useful for unstructured data.
Relational databases: Store data in a tabular form. This type is ideal for scenarios where understanding data relationships is required.
E. Orchestration
Orchestration in data pipeline architecture helps manage the flow and processing of data. Key components of pipeline orchestration include:
Workflow automation: Automates repetitive tasks to increase efficiency.
Task scheduling: Aligns tasks with business cycles and operational schedules to optimize the data processing timing.
Dependency management: Guarantees that each process is executed in the correct order which is crucial for maintaining data integrity.
F. Monitoring
Monitoring is the continuous oversight of the pipeline and focuses on maintaining its health and efficiency. This involves several important elements, like:
Performance metrics: Tracks the efficiency of the data pipeline to identify bottlenecks and performance issues.
Alert systems: Provides immediate notifications about any operational issues. This helps provide quick responses to prevent data loss or corruption.
Optimization: Continuous assessment and improvement of the pipeline which is essential for adapting to changing data needs and business requirements.
7 Common Data Pipeline Architecture Patterns
To choose the right approach for your data needs, understand different data pipeline architecture patterns. Let’s discuss them in detail.
I. Batch Processing

Batch processing is a traditional data pipeline method where data is collected over a specified period and then processed in large groups or batches. This method uses scheduled processing and is helpful when dealing with massive data volume. The main focus here is on processing efficiency rather than immediacy.
Key Considerations
Suitability: Best for scenarios where data can be collected and processed later without an immediate need for results, like historical data analysis.
Challenges: Handling large data volumes can be resource-intensive and there is a latency between data collection and the result availability.
II. Stream Processing

Stream processing continuously ingests and processes data in near real-time. This architecture pattern is designed for rapid response and is suitable for handling data that is constantly generated. It is essential in scenarios where even a slight delay in data processing can cause significant consequences.
Key Considerations
Suitability: Ideal for applications like real-time analytics, monitoring systems, and instant decision-making processes.
Challenges: Requires robust infrastructure to handle continuous data streams and maintain low latency.
III. Lambda Architecture
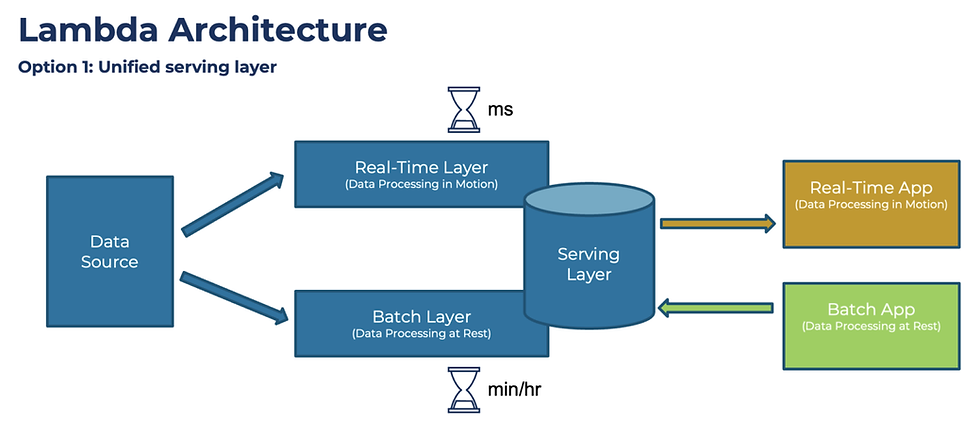

Lambda architecture combines the strengths of both batch and stream processing into a single pipeline. It maintains 2 layers: a batch layer for handling large datasets and a speed layer for processing real-time data. This dual approach provides a comprehensive solution and caters to both in-depth analytics and real-time processing needs.
Key Considerations
Suitability: Effective for applications requiring historical data analysis alongside real-time data processing, like advanced analytics in eCommerce.
Challenges: Complexity in managing and synchronizing 2 separate layers of data processing.
IV. Kappa Architecture

Kappa architecture simplifies Lambda Architecture by focusing solely on stream processing. It treats all data as a continuous stream, handling real-time and historical data analysis uniformly. It reduces complexity and is used in systems where real-time processing is essential.
Key Considerations
Suitability: Suitable for situations where real-time data analytics are critical, like in IoT applications.
Challenges: Managing historical data solely through streaming can be challenging, especially for extensive historical data.
V. ETL Architecture (Extract Transform Load)

ETL architecture is a foundational pattern in data warehousing. It involves extracting data from various sources, transforming it into a structured format, and loading it into a data warehouse or similar repository. This structured approach is useful for data integration and preparing data for business intelligence and analytics.
Key Considerations
Suitability: Common in scenarios involving data migration and integration, where data from various sources is consolidated.
Challenges: The process can be time-consuming and the sequential nature might not be suitable for real-time data needs.
VI. ELT (Extract Load Transform) Architecture

ELT architecture represents a modern approach to data processing, where data is first extracted from various sources and immediately loaded into a data storage system. The data transformation occurs within the storage environment, using its processing capabilities.
Unlike traditional ETL methods, this approach transforms data once it is already in the target system, rather than doing so beforehand.
Key Considerations
Suitability: ELT is highly effective for handling large volumes of data where the data schema is not predefined or needs to be adaptable. This makes it useful for cloud-based data warehouses or data lakes that require flexible and dynamic data processing.
Challenges: The primary challenge with ELT is maintaining data quality and security since the data is loaded in its raw form. It also requires substantial processing power in the data storage system which is essential for efficient and scalable data handling.
VII. Data Lake Architecture

Data lake architecture revolves around storing raw data in its native format in a data lake. This method provides greater flexibility in data storage and processing as data can be stored without predefined schemas and processed as needed.
Key Considerations
Suitability: Ideal for organizations that collect and store vast amounts of varied data types, like large enterprises with diverse data sources.
Challenges: Risk of becoming a “data swamp” if not managed properly. The lack of structure can cause difficulties in data retrieval and quality maintenance.
9 Factors You Should Consider To Design Optimal Data Pipelines
The choice of a data pipeline design pattern matters for how well it handles data. But before you make your pick, there are different factors that you should consider. Let’s discuss them in detail.
1. Data Processing
The data processing method is crucial in determining the right pipeline design. Batch processing, ideal for handling data in set intervals, is the preferred choice for situations where immediate data analysis isn’t a priority. On the other hand, streaming data processing is necessary for real-time analysis and quick decision-making.
When choosing, assess whether your data is time-sensitive and requires immediate processing, or if it can be collected and processed in large batches.
2. Technology Stack & Infrastructure
Your existing technological environment has a major influence on your pipeline design. A cloud-based setup offers scalability and flexibility which are essential for handling large-scale data and diverse data sources. On the other hand, on-premises solutions offer better control and security which are crucial for sensitive data.
3. Data Transformation Needs
When deciding, consider the complexity and volume of your data transformation needs to select a pattern that efficiently manages these tasks.
ETL processes are ideal for structured data transformation before storage and are common in data warehousing. ELT, on the other hand, offers more flexibility for large data sets by transforming data after it is loaded into the system.
4. Change Data Capture (CDC)
CDC is instrumental in maintaining up-to-date data by capturing changes as they occur. This approach is particularly beneficial in dynamic environments where data is constantly updated and requires real-time synchronization.
If your operations demand keeping track of every data modification, prioritize pipeline patterns that seamlessly integrate or support CDC functionalities.
5. Pipeline Complexity
The complexity level of your pipeline directly impacts its design. Simple pipelines that focus on direct data transfer without modification are straightforward but limited in functionality.
Complex pipelines, incorporating multiple processing and transformation steps, offer more versatility but require advanced management. Your choice should align with the complexity level of your data operations.
6. Modular Design
Modular design gives you more flexibility and scalability. This makes it easier to maintain and update as each component can be modified independently. Modular design is ideal for evolving data environments where quick adaptation to new requirements is needed.
7. Downstream Requirements
Make sure that your pipeline output is compatible with target systems, whether it is for analytics, reporting, or operational use. Always select a pattern that facilitates efficient data flow and integration and meets your specific downstream needs like format compatibility and timely data availability.
8. Pipeline Representation & Design Interface
Visual interfaces that offer a graphical representation of the data flow help in easier understanding and modification of the pipeline. Choose a design that provides a comprehensive view of the pipeline’s structure and flow for better management and troubleshooting.
9. Monitoring & Operating The Pipeline
Efficient monitoring and operational capabilities help maintain your pipeline’s health and performance. Opt for a design that allows for easy tracking of data flow, error handling, and performance metrics. A pattern with strong monitoring and operational tools lets you track the pipeline reliability and minimizes downtime.
Unlocking Real-Time Analytics With Timeplus In Your Data Pipeline

Timeplus is a dynamic, streaming-first data analytics platform that can seamlessly integrate into various data pipeline architectures. The best part is it can manage both real-time and historical data. This helps in real-time data processing where immediacy and accuracy are paramount.
Built on the advanced Proton, an open-source streaming database, Timeplus combines advanced technology with practical application. It is flexible and user-friendly which makes it an ideal fit for any organization’s data system, regardless of its size and nature.
Timeplus is especially beneficial for data and platform engineers as it simplifies extracting valuable insights from streaming data with SQL.
Timeplus Integration With Key Components Of Data Pipeline
Timeplus can ingest real-time streaming data from various sources. This guarantees that the data pipeline architecture remains agile and responsive to immediate data inputs.
With Timeplus, you can immediately transform streaming data into actionable insights which is an important requirement in industries like finance and eCommerce.
Incorporating Timeplus into pipeline orchestration provides seamless real-time data workflow management and ensures timely execution and data consistency.
Timeplus offers advanced monitoring capabilities for the real-time data stream. This helps optimize performance and quickly identify issues in the pipeline.
Timeplus In Various Data Pipeline Architecture Patterns
Timeplus is particularly beneficial in stream processing architectures as it provides low-latency analysis and immediate feedback on streaming data.
In Lambda architecture, Timeplus can enhance the real-time processing layer to balance both historical batch analysis and real-time data streaming needs.
While primarily known for real-time capabilities, Timeplus provides a layer for real-time data exploration and quick insights to support ETL and Data Lake architecture.
Conclusion
When it comes to data pipeline architecture, think strategically. Take the time to plan and design it carefully – it is worth the effort. It is an upfront investment that pays off big in terms of operational efficiency, scalability, reliability, and decision-making speed.
Timeplus optimizes data pipelines with its versatile real-time and historical data processing capabilities and integrates smoothly into modern data environments. Its high-performance streaming analytics can ingest, process, and analyze real-time data at scale. You get complete visibility into your data as it flows through the pipeline.
Get a live demo today or try Timeplus for free to experience the agility and efficiency it brings to your streaming data workflows.


